Radiologists should keep the threads in their hands
It can process exorbitant amounts of data in a very short time. While artificial intelligence is seen as offering great potential in medicine, the final decision should remain in the hands of medical professionals, says researcher David Major of the Center for Virtual Reality and Visualization (VRVis), who pulls the strings in the background of artificial networks.
Claudia Tschabuschnig
"There are always edge cases where computer systems stand on the tipping point."
It may sound promising: a diagnosis made automatically in no time at all. In radiology in particular, artificial machines are supposed to show off all their strengths. On the other hand, there is the black box problem, missing medical data and difficult diagnostic cases. Major, who is working on the promising technology that is intended to support radiologists in their daily work, explains what this is all about.
medinlive: There are countless terms surrounding artificial intelligence. What are artificial neural networks? And what does the term deep learning stand for?
Major: Artificial neural networks can be used to solve various problems in a computer-based way. They are inspired by the human brain and can be used for machine learning and artificial intelligence. Similar to our brain, they consist of neurons that are connected to each other, perform mathematical operations and pass on information. Deep learning (multilayer learning or deep learning, ed.) is a machine learning method that applies neural networks to problem solving and is an umbrella term for "artificially" generating knowledge from experience (see info box below for more on how neural networks work). Whereas earlier, conventional methods required patterns or features to look out for to be defined manually and often with expert knowledge, with Deep Learning this happens automatically in an AI model. Examples of conventional machine learning methods are feature extraction methods, such as metrics of gray value histograms or gray value matrices in combination with, for example, a Support Vector Machine (a method that divides patterns into classes, note) or Decision Trees (methods that learn and represent a predictive model in terms of tree structures, note).
medinlive: You work with medical images. How do you operate?
Major: First, we choose a network architecture according to the task to be accomplished. We generally use Convolutional Neural Networks (CNNs) in terms of their type, since these networks are designed to process images. For example, the task may be categorization or classification (such as: "sick"-"not sick" or "not sick" and "what disease") or segmentation, where images are divided into sections. An example is the categorization of lung x-rays into classes such as healthy, tuberculosis, or pneumonia. Segmentation is used in tumor detection, for example, where the tumor is outlined, its size determined, and tracked over time. These two methods make up much of what is being worked with in medical applications of AI. Sample data is used to train the network, and the main focus is on optimization, i.e. error minimization, but also on the proper preparation and composition of the training data. An important requirement for error minimization is that the example images are labeled with the correct diagnosis. This way, the error between the output of the AI model and the correct diagnosis of the images can be measured. This is called supervised learning.
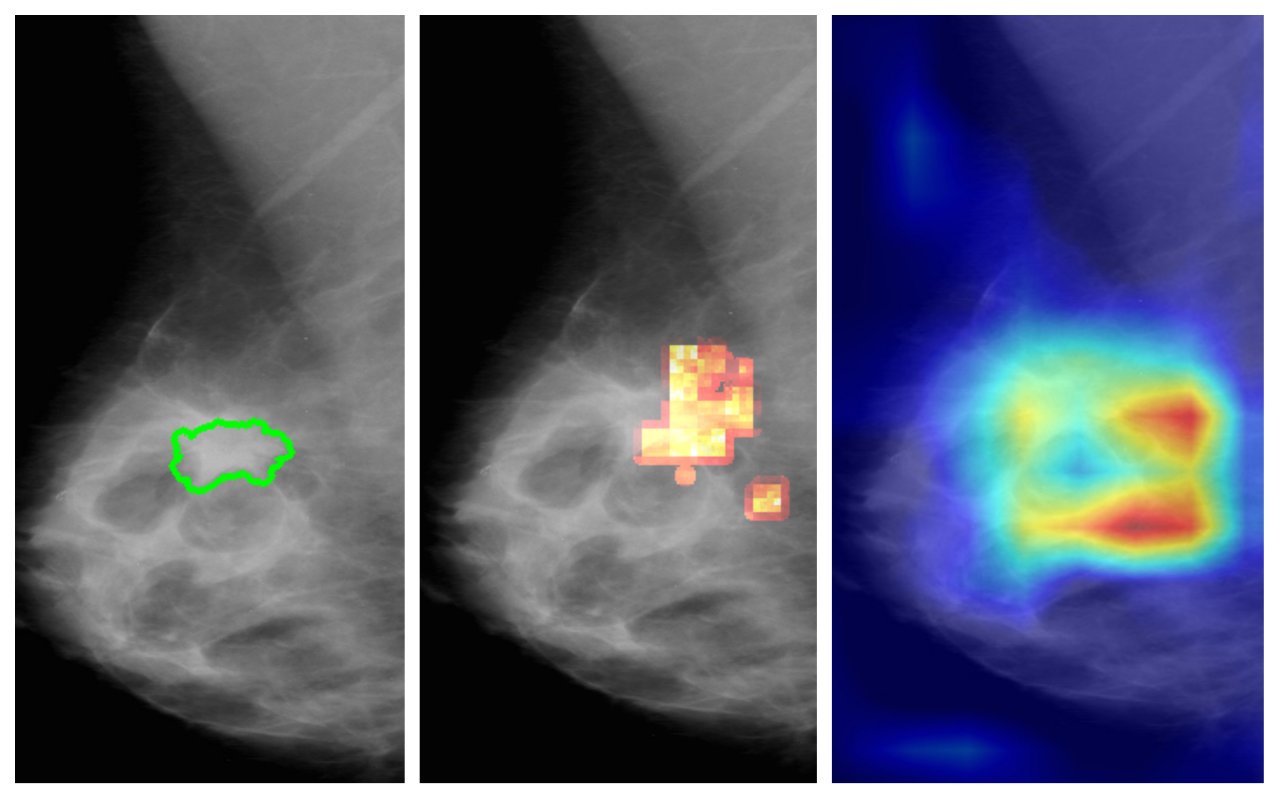
Visualization method for determining crucial image regions of an AI model: (a) original with annotated findings, (b) heat map of the method of vrvis , (c) heat map of an industry standard solution (GradCAM).
medinlive: Is it still comprehensible for you how the model comes to the result, or does it remain a black box?
Major: The result is difficult for us to comprehend, because such a network consists of many building blocks. In one of my recent research papers, the goal was to understand the decision-making process of an AI model. This model met the annotation "sick"-"not sick." In doing so, we wanted to figure out which location on a medical image was critical to the network's decision. This is often visualized using heat maps (similar to a thermal image, note). However, existing methods have not provided reliable results in the context of medical data. This gap could now be closed with the method we developed.
medinlive: Are there similarities in the way the human brain and artificial networks function?
Major: There are various opinions on this. In any case, the human brain is much more complex. The networks, i.e. neurons and their connection are, in my opinion, the only similarity. It is believed that the hierarchical processing of information in a neural network resembles that of the visual cortex. The artificial networks used today work well for very specific, well-defined tasks. One cannot easily create a self-learning model that is universally applicable and makes decisions by itself. Even if AI models get better, in radiology the doctor must have the last word.
medinlive: Why?
Major: For the final medical decision, you need much more complex knowledge and therefore everything that humans are good at, such as decision making in complex problems where many factors can play a role. Today's networks cannot yet reflect this complexity with the necessary precision in the medical context. Another weakness concerns variance. The human brain is still better at transferring knowledge, i.e. recognizing objects from other perspectives. Artificial systems are not as good at this. There are always medical borderline cases where computer systems are on the edge. That's why you need doctors to make a final decision. In some cases, you have to resort to a biopsy, for example. Also machines make numerous mistakes and often cannot be trained properly. They can't see as much data and absorb as much knowledge as a radiologist. Quite often, these models are trained with a small data set, which always includes bias (a bias, note). On the other hand, there is also the problem with face recognition that there is too much data of faces with light skin color, which leads to bias and discrimination. This debate has not yet been resolved. There are also obstacles in obtaining medical data in particular. The introduction of the General Data Protection Regulation has made it even more difficult to obtain this data. It would in fact also be interesting to have access to follow-up data in order to be able to monitor the growth and changes of a disease.
medinlive: Are there fundamental efforts to make images also publicly available to several researchers?
Major: There are publicly available datasets (such as the Cancer Imaging Archive) that are made available, for example, through competitions. Research groups can work on those, which works well. Unfortunately, how to get medical data more easily has not yet been solved. In addition, one could work with diagnostic centers and set up a project.
Deep learning is very data hungry. You need a lot of data to end up with a good working model that can work with future data. There are more and more radio technologists who also have knowledge toward artificial intelligence. credit: pixabay
medinlive.: Then there is the possibility of artificially producing data by means of Generative Adversarial Networks (GAN) ("generating generic networks", which consist of two artificial neuronal networks that perform a zero-sum game, note). Is that an issue in your work as well?
Major: It's an issue, but it's very sensitive, because the extent to which a machine-generated image really accurately represents anatomical features and pathology is questionable. Such issues should be analyzed closely with physicians. However, this method could currently help to develop new drugs, for example.
medinlive: What questions do you have for radiologists?
Major: It is important for us to see how physicians tackle certain problems or tasks. Researchers, after all, need the images to be labeled with the correct diagnosis, and this input has to come from radiologists. If we don't get enough annotations, we can't build a good model. Deep learning is very data hungry. You need a lot of data to end up with a good working model that can work with future data. There are more and more radio technologists who also have knowledge toward artificial intelligence. This trend can help to foster collaboration between us and radiologists.
medinlive: Which methods do you currently use to evaluate outputs?
Major: There are several methods. For example, accuracy evaluation is one such measure that indicates how many images were correctly assigned in the end. We use the radiologists' annotation for that. Basically, what happens is that we divide the data into training data, evaluation data, and test data. With training data, the model learns. With assessment data, parameters are set, such as how long the training lasts. If it is determined that the error on the assessment data cannot be further minimized, the training is stopped. There is also the test data, which should not be touched in the whole process. They represent the future data, that is, the data that could be seen in practice. Basically, this is all different data from different patients, but of the same type, which the trained network is then also supposed to process or assess.
medinlive: Artificial intelligence is often associated with time optimization. How long does the process before that - the training process - take on average?
Major: That depends on the task, the amount of data and the technical resources. The reason why Deep Learning models have become popular is because the graphics cards have been continuously optimized. Training the model can take hours to days. With less data, it takes about three to five hours, but with hundreds, thousands or millions of data, it would take days. However, if one were to bring in more powerful graphics cards, such as Google's Tensor Processing Units (TPU), one could train with millions of data sets even within hours.
medinlive: What is important when using AI models in medical practices?
Major: The most important thing, in my opinion, is to use these technologies in the right place in everyday clinical practice, which is not happening at the moment. This topic was also recently discussed at the ECR radiology conference in Vienna. Basically, you would have to ask radiologists where they need support or automation to increase efficiency, effectiveness and all these factors. For example, in lung tumor screening, if you see a lump on a scan, you outline it, measure it, and make notes about it. The question is what can be done to make this happen faster. An AI model could do this outlining better than a human, and the doctor or physician could then check it and correct it if necessary. The documentation process has another potential that can be structured and automated as well.
The architecture of AI models. How do artificial neural networks work?
The theory of neural networks has its origins in the 1950s. In 1958, Frank Rosenblatt published the perceptron model, which is still the basis of artificial neural networks today. It is a classical solution of how relations and relationships are coded and recognized. In principle, it is a simplified artificial neural network, which in its basic version consists of a single artificial neuron with adjustable weights and a threshold. A neuron is linked to multiple inputs and produces a binary output. The connections between the inputs and the neuron are weighted according to the relevance of the input units. The binary output is generated by the activation process, where it is checked whether the weighted sum of the inputs exceeds a certain threshold.
A collection of neurons forms a "layer" and several such "layers" connected together form a deep artificial neural network.
A special and popular type of neural networks are Convolutional Neural Networks (CNNs), which are especially useful for visual recognition of objects in images and videos. As the name Convolutional implies, the way the networks are constructed includes a mathematical operation called convolution. Convolution involves multiplying image regions by a convolution kernel or filter and adding the product terms. An example of a filter is the edge filter. The goal in the learning process is to learn filter patterns that emphasize aspects of the image that are critical to the task at hand. Besides the convolutions, there are also so-called pooling operations in an ordinary CNN. These reduce the size of the image, in the simplest case the width and height are each halved by taking the maximum value from each 2×2 pixel. The goal of the reduction is to make structural relationships in the image clearer. In a typical architecture of an ordinary CNN, convolutional layers followed by pooling layers are repeated several times. The intermediate images created by applying convolution and pooling are called feature maps. The first layers typically activate edge-like features, the middle layers detect concepts such as wheels, windows, and the last layers detect features that are crucial for the final classification of an image such as in a car or house when applying CNNs to photos.
The principle of the perceptron is that on which artificial systems are based. According to brain researcher Wolf Singer, the difference between artificial and natural systems is also the reciprocity of the connections. This is because in artificial systems, the flow of information goes in only one direction, whereas the study of macaque brains shows that there are hundreds of thousands of nerve fibers between the brain areas, which go in thousands of directions and form a densely networked system.
Since 2000, the term Deep Learning has been used primarily in the context of artificial neural networks.
The Center for Virtual Reality and Visualization (VRVis) is the largest independent research center in the field of visual computing (image informatics or graphical data processing) in Austria and, with its more than 70 employees, conducts innovative research and development projects in cooperation with industrial companies and universities. www.vrvis.at VRVis is one of the COMET competence centers of level K1 and thus, together with the COMET competence centers of the top level K2, is one of the federally funded centers of Austrian technology policy.
David Major is a researcher in the Biomedical Image Informatics research group at VRVis, the Center for Virtual Reality and Visualization. Major's research focuses on the application of AI models to image analysis in radiology.
David Major is a researcher in the Biomedical Image Informatics research group at VRVis(Center for Virtual Reality and Visualization). His research focuses on the application of AI models for image analysis in radiology.
VRVis
"Deep learning is very data hungry. You need a lot of data to end up with a good working model that can work with future data."